ClickHouse的架构概述
ClickHouse的核心特性
完备的DBMS功能
ClickHouse拥有完备的管理功能,所以它称得上是一个 DBMS(Database Management System,数据库管理系统)
- DDL :可以动态地创建、修改或删除数据库、 表和视图,而无须重启服务。
- DML:可以动态查询、插入、修改或删除数 据。
- 权限控制:可以按照用户粒度设置数据库或者表的操作权限,保 障数据的安全性。
- 数据备份与恢复:提供了数据备份导出与导入恢复机制,满足生 产环境的要求。
- 分布式管理:提供集群模式,能够自动管理多个数据库节点。
分布式存储与数据压缩
列式存储与按行存储相比,可以有效地减少查询时所需扫描地数据量,按列存储地另外一个优势是对数据压缩的友好性,列式存储是数据压缩地前提,列与列之间由不同的文件分别保存(这里主要指MergeTree表引擎),数据默认使用LZ4算法压缩。
数据压缩示例:
压缩前:abcdefghi_bcdefghi
压缩后:abcdefghi_(9,8)
向量化执行引擎
向量化执行,可以简单地看作一项消除程序中循环的优化,为了实现向量化执行,需要利用CPU的SIMD指令。SIMD的全称是 Single Instruction Multiple Data。即用单条指令操作多条数据,通过数据并行提高性能的一种实现方式,它的原理是在CPU寄存器层面实现 数据的并行操作。
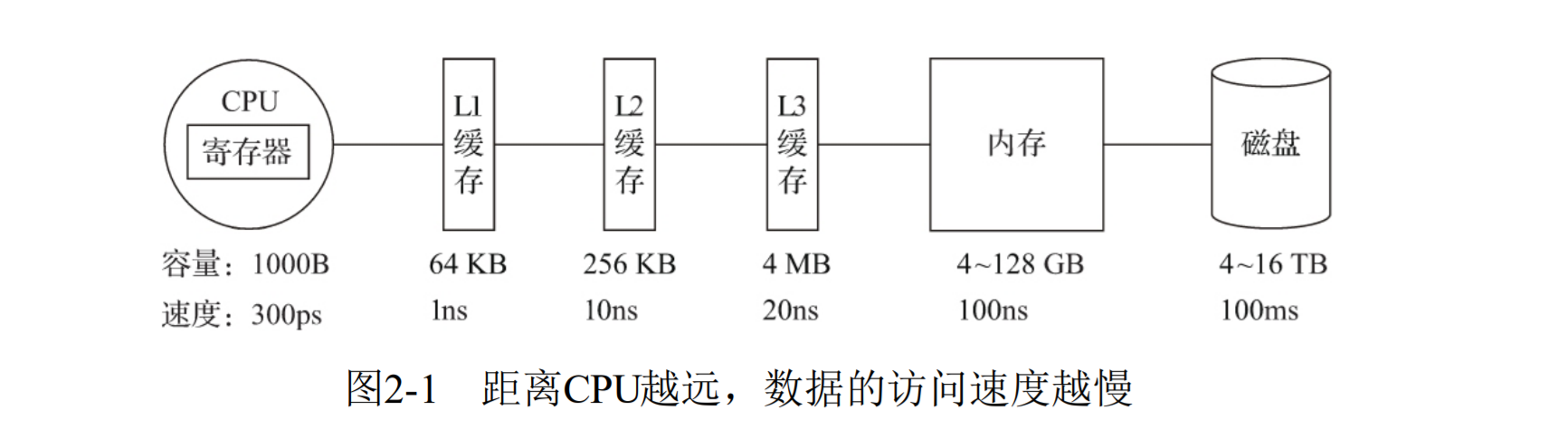
存储媒介距离CPU越近,访问速度越快,使用CPU向量化执行的特性,对程序的性能提升很大,ClickHouse目前利用SSE4.2指令集实现向量化执行。
关系模型与SQL查询
ClickHouse使用关系模型 描述数据并提供了传统数据库的概念(数据库、表、视图和函数 等)完全使用SQL作为查询语言,SQL大小写敏感。
多样化的表引擎
ClickHouse使用关系模型 描述数据并提供了传统数据库的概念(数据库、表、视图和函数 等),,ClickHouse 共拥有合并树、内存、文件、接口和其他6大类20多种表引擎。
多线程与分布式
多 线程处理就是通过线程级并行的方式实现了性能的提升,相比基于底 层硬件实现的向量化执行SIMD,线程级并行通常由更高层次的软件层 面控制,和向量化执行形成互补.
ClickHouse在数据存取方面,既支持分区(纵向扩 展,利用多线程原理),也支持分片(横向扩展,利用分布式原 理).
多主架构
HDFS、Spark、HBase和Elasticsearch这类分布式系统,都采用了 Master-Slave主从架构,由一个管控节点作为Leader统筹全局。而 ClickHouse则采用Multi-Master多主架构,集群中的每个节点角色对 等,客户端访问任意一个节点都能得到相同的效果.
在线查询
ClickHouse与其他分析型数据库对比,比如 Vertica、SparkSQL、Hive和Elasticsearch,这些分析型数据库,它们都可以支撑海量数据的查询场景,都拥有 分布式架构,都支持列存、数据分片、计算下推等特性。
ClickHouse对比下的优势:适用于复杂查询,又快又开源。
Vertica格高昂、SparkSQL与Hive这类系统无法保障90%的查询在1秒内返回,查询分钟级响应,Elasticsearch搜索引擎在处理亿级数据聚合查询时效率低。
数据分片与分布式查询
数据分片是将数据进行横向切分,ClickHouse支持分片,每个分片对应ClickHouse的一个服务节点,分片的上限取决于节点数。
ClickHouse提供了本地表与分布式表的概念,一张本地表相当于一份数据分片,分布式表不存储任何数据,他是本地表的访问代理,作用类似于分库中间件,借助分布式表,代理访问多个数据分片,实现分布式查询。
ClickHouse的架构设计
Column与Field
Column和Field是ClickHouse数据最基础的映射单元,内存中的一列 数据由一个Column对象表示,Field对象代表一个单值,单列中的一行数据。
DataType
DataType负责数据的序列化与反序列化,IDataType接口定 义正反序列化的方法。
Block与Block流
ClickHouse内部的数据操作是面向Block对象进行的,并且采用了 流的形式,Block对象的本质是由数据对象、数据类型和列名称组成的三元 组,即Column、DataType及列名称字符串。
Table
使用 IStorage接口指代数据表,表引擎是ClickHouse的一个显著特性,不同 的表引擎由不同的子类实现。
Parser与Interpreter
Parser分析器负责创建 AST对象;而Interpreter解释器则负责解释AST,并进一步创建查询的 执行管道,它们与IStorage一起,串联起了整个数据查询的过程。
Functions与Aggregate Functions
ClickHouse主要提供两类函数——普通函数和聚合函数。普通函 数由IFunction接口定义,拥有数十种函数实现,例如 FunctionFormatDateTime、FunctionSubstring等,聚合函数由IAggregateFunction接口定义,相比无状态的普通函 数,聚合函数是有状态的。
Cluster与Replication
ClickHouse的集群由分片(Shard)组成,而每个分片又通过副本 (Replica)组成 。
- ClickHouse的1个节点只能拥有1个分片,也就是说如果要实 现1分片、1副本,则至少需要部署2个服务节点
- 分片只是一个逻辑概念,其物理承载还是由副本承担的。
ClickHouse为何如此之快
- 列式存储
- 向量化引擎
- 着眼硬件,先想后做,充分考虑硬件性能带来的提升。
- 算法在前,抽象在后,对于常量,使用Volnitsky算法;对于 非常量,使用CPU的向量化执行SIMD,暴力优化;正则匹配使用re2 和hyperscan算法。性能是算法选择的首要考量指标。
- 勇于尝鲜,不行就换。
- 特定化场景、特殊优化。根据数据量的不同,场景不同,选择不同的算法进行处理。
- 持续测试,持续改进。真实数据做测试验证,快速迭代下进行持续改进。
第三章 ClickHouse的安装与部署
ClickHouse安装过程
ClickHouse可以在任何具有x86_64,AArch64或PowerPC64LE CPU架构的Linux,FreeBSD或Mac OS X上运行。
官方预构建的二进制文件通常针对x86_64进行编译,并利用SSE 4.2指令集,因此,除非另有说明,支持它的CPU使用将成为额外的系统需求。下面是检查当前CPU是否支持SSE 4.2的命令:
$ grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
Ubuntu的官方预编译deb软件包。运行以下命令来安装包:
sudo apt-get install apt-transport-https ca-certificates dirmngr
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv E0C56BD4
echo "deb https://repo.clickhouse.com/deb/stable/ main/" | sudo tee \
/etc/apt/sources.list.d/clickhouse.list
sudo apt-get update
sudo apt-get install -y clickhouse-server clickhouse-client
sudo service clickhouse-server start
clickhouse-client
Mac下单机安装部署Clickhouse
1、安装docker
2、安装ClickHouse
客户端:docker pull yandex/clickhouse-client
服务端:docker pull yandex/clickhouse-server
3、命令启动镜像或者docker控制台启动
docker run -d --name ch-server --ulimit nofile=262144:262144 -p 8123:8123 -p 9000:9000 -p 9009:9009 yandex/clickhouse-server
4、启动命令
clickhouse-client
5、使用idea 连接clickhouse 做数据增删改查。
ClickHouse客户端的访问接口
ClickHouse的底层访问接口支持TCP和HTTP两种协议,TCP协议拥有更好的性能,其默认端口为9000,而HTTP协议则拥有更好的兼容性,可以通过 REST服务的形式被广泛用于JAVA、Python等编程语言的客户端,其默 认端口为8123.
ClickHouse支持标准的JDBC协议,底层基于HTTP接口通信.
JDBC访问ClickHouse
1、引入Maven依赖
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.2.4</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.11.0</version>
</dependency>
2、连接JDBC操作ClickHouse
public static void main(String[] args) throws ClassNotFoundException, SQLException {
// 初始化驱动
Class.forName("ru.yandex.clickhouse.ClickHouseDriver");
// url
String url = "jdbc:clickhouse://localhost:8123";
// 用户名密码
String user = "default";
String password = "";
// 登录
Connection con = DriverManager.getConnection(url, user, password);
Statement stmt = con.createStatement();
// 查询
ResultSet rs = stmt.executeQuery("SELECT 1");
rs.next();
System.out.printf("res " + rs.getInt(1));
}
高可用集群模式操作
高可用模式允许设置多个host地址,每次会从可用的地址中随机 选择一个进行连接,在高可用模式下,需要通过BalancedClickhouseDataSource对象获 取连接。
public static void main(String[] args) throws SQLException {
//多个地址使用逗号分隔
String url = "jdbc:clickhouse://localhost:8123,localhost:8123/default";
//设置JDBC参数
ClickHouseProperties clickHouseProperties = new ClickHouseProperties();
clickHouseProperties.setUser("default");
//声明数据源
BalancedClickhouseDataSource balanced = new BalancedClickhouseDataSource(url,
clickHouseProperties);
//对每个host进行ping操作, 排除不可用的dead连接
balanced.actualize();
//获得JDBC连接
Connection con = balanced.getConnection();
Statement stmt = con.createStatement();
//查询
ResultSet rs = stmt.executeQuery("SELECT 1 , hostName()");
rs.next();
System.out.println("res "+rs.getInt(1)+","+rs.getString(2));
}
第四章:数据定义
ClickHouse的数据类型
基础类型
基础类型只有数值、字符串和时间三种类型,没有Boolean类型, 但可以使用整型的0或1替代。
数值类型
- Int类型,使用Int8、Int16、Int32和Int64指代4种大 小的Int类型,可对应mysql中的Tinyint、Smallint、Int和Bigint,支持无符号数,分别用Uint8、Uint16、Uint32、Uint64表示。
Float类型,使用Float32和Float64代表单精度浮点 数以及双精度浮点数,Float32有效精度7位,Float64有效精度16位,支持正无穷、负无穷、非数字的表达式。
Decimal, ClickHouse提 供了Decimal32、Decimal64和Decimal128三种精度的定点数
- 简写方式: Decimal32(S) 等效于Decimal(1-9,S) 、Decimal64(S) 等效于Decimal(10-18,S) 、 Decimal128(S) 等效于Decimal(19-38,S) 三种
- 原生方式:Decimal(P,S),P代表精度,决定总位数(整数部分+小数部分),取值范围是1 ~38,S代表规模,决定小数位数,取值范围是0~P。
- 字符串类型:分为String、FixedString和UUID三类
- 字符串由String定义,长度不限
- FixedString类型,定长字符串类型,和传统意义上的Char类型有些类似,定长字符串通过 FixedString(N)声明,其中N表示字符串长度。
- UUID共有32位,它的格式为8-4-4-4-12,如: 4d4d4a1d-c30c-4727-bade-298a1930231f
时间类型
- DateTime :DateTime类型包含时、分、秒信息,精确到秒,支持使用字符串形 式写入
- DateTime64:DateTime64可以记录亚秒,它在DateTime之上增加了精度的设置
- Date:Date类型不包含具体的时间信息,只精确到天,它同样也支持字符 串形式写入
复合类型
- 数组类型 Array
- 例子:SELECT tuple(1,’a’,now()) AS x, toTypeName(x)
- 定义字段:CREATE TABLE Array_TEST ( c1 Array(String) ) eng
- Tuple:元组类型由1~n个元素组成,每个元素之间允许设置不同的数据 类型,且彼此之间不要求兼容
- 例子:SELECT tuple(1,’a’,now()) AS x, toTypeName(x)
- 定义字段:CREATE TABLE Tuple_TEST ( c1 Tuple(String,Int8) ) ENGINE = Memory;
Enum类型:提供了Enum8和Enum16两种枚举类型,
- 定义字段:CREATE TABLE Enum_TEST ( c1 Enum8(‘ready’ = 1, ‘start’ = 2, ‘success’ = 3, ‘error’ = 4) ) ENGINE = Memory;
- 注意:Key和Value是 不允许重复的,要保证唯一性。其次,Key和Value的值都不能为 Null,但Key允许是空字符串
Nested:嵌套类型:一张数据表,可以定义 任意多个嵌套类型字段,但每个字段的嵌套层级只支持一级,即嵌套 表内不能继续使用嵌套类型。
- 定义语句:CREATE TABLE nested_test ( name String, age UInt8 , dept Nested( id UInt8, name String ) ) ENGINE = Memory;
特殊类型
- Nullable
- Domain: 域名类型:域名类型分为IPv4和IPv6两类,本质上它们是对整型和字符串的 进一步封装。IPv4类型是基于UInt32封装的
如何定义数据表
ClickHouse一共支持五种引擎
- Ordinary:默认引擎,在绝大多数情况下我们都会使用默认引 擎,使用时无须刻意声明。在此数据库下可以使用任意类型的表引 擎。
- Dictionary:字典引擎,此类数据库会自动为所有数据字典创建 它们的数据表
- Memory:内存引擎,用于存放临时数据。此类数据库下的数据 表只会停留在内存中,不会涉及任何磁盘操作,当服务重启后数据会 被清除。
- Lazy:日志引擎,此类数据库下只能使用Log系列的表引擎
- Mysql:mysql引擎:此类数据库下会自动拉取远端MySQL中 的数据,并为它们创建MySQL表引擎的数据表。
基本DDL操作
删除数据库、删除表
DROP DATABASE [IF EXISTS] db_name
DROP TABLE [IF EXISTS] table_name
数据表
建表语句
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name (
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
省略…
) ENGINE = engine
复制其他表结构:
复制表
CREATE TABLE [IF NOT EXISTS] [db_name1.]table_name AS [db_name2.] table_name2
[ENGINE = engine]
--创建新的数据库
CREATE DATABASE IF NOT EXISTS new_db
--将default.hits_v1的结构复制到new_db.hits_v1
CREATE TABLE IF NOT EXISTS new_db.hits_v1 AS default.hits_v1 ENGINE = TinyLog
//select方式复制
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name ENGINE = engine AS SELECT …
例子:
create table test1 ENGINE = TinyLog AS select * from test;
create table test3 ENGINE = TinyLog AS test1 ENGINE = TinyLog;
默认表示值
表字段支持三种默认值表达式的定义方法,分别是DEFAULT、 MATERIALIZED和ALIAS。
CREATE TABLE dfv_v1 (
id String,
c1 DEFAULT 1000,
c2 String DEFAULT c1
) ENGINE = TinyLog
修改默认值
ALTER TABLE [db_name.]table MODIFY COLUMN col_name DEFAULT value
临时表
创建临时表,临时表引擎是内存,如果会话结束、表会被销毁。
CREATE TEMPORARY TABLE [IF NOT EXISTS] table_name (
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
)
分区表
数据分区(partition)和数据分片(shard)是完全不同的两个概 念。数据分区是针对本地数据而言的,是数据的一种纵向切分。而数 据分片是数据的一种横向切分
CREATE TABLE partition_v1 (
ID String,
URL String,
EventTime Date
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventTime)
ORDER BY ID
视图
ClickHouse拥有普通和物化两种视图,其中物化视图拥有独立的 存储,而普通视图只是一层简单的查询代理
数据表的基本操作
追加新字段
ALTER TABLE testcol_v1 ADD COLUMN OS String DEFAULT 'mac'
//在指定字段后面追加
ALTER TABLE testcol_v1 ADD COLUMN IP String AFTER ID
修改数据类型
ALTER TABLE tb_name MODIFY COLUMN [IF EXISTS] name [type] [default_expr]
//例子
ALTER TABLE testcol_v1 MODIFY COLUMN IP IPv4
修改备注
ALTER TABLE testcol_v1 COMMENT COLUMN ID '主键ID'
删除已有字段
ALTER TABLE tb_name DROP COLUMN [IF EXISTS] name
ALTER TABLE testcol_v1 DROP COLUMN UR
清空数据表
TRUNCATE TABLE db_test.testcol_v2
数据分区的基本操作
删除指定分区
ALTER TABLE partition_v2 DROP PARTITION 201907
复制分区数据
适用于快速数据写入、多表间数据同步和备份等场景,复制的前提条件,两张表需要拥有相同的分区键,它们的表结构完全相同。
ALTER TABLE B REPLACE PARTITION partition_expr FROM A
重置分区数据
如果数据表某一列的数据有误,需要将其重置为初始值,此时可 以使用下面的语句实现:
ALTER TABLE tb_name CLEAR COLUMN column_name IN PARTITION partition_expr
//例子
ALTER TABLE partition_v2 CLEAR COLUMN URL in PARTITION 201908
分布式DDL执行
如果在集群中任意一个节点上执行DDL 语句,那么集群中的每个节点都会以相同的顺序执行相同的语句。
加上ON CLUSTER cluster_name声明即可 ,执行命令
CREATE TABLE partition_v3 ON CLUSTER ch_cluster(
ID String,
URL String,
EventTime Date
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventTime)
ORDER BY ID
数据的写入
支持批量插入
//支持批量插入
INSERT INTO partition_v2 VALUES ('A0011','www.nauu.com', '2019-10-01'),
('A0012','www.nauu.com', '2019-11-20'),('A0013','www.nauu.com', '2019-12-20')
//支持表达式或函数
INSERT INTO partition_v2 VALUES ('A0014',toString(1+2), now())
//select 查询写入
INSERT INTO partition_v2 SELECT * FROM partition_v1
数据的删除和修改
ClickHouse提供了DELETE和UPDATE的能力,这类操作被称为 Mutation查询,不支持事务,异步执行。hexo g -dg
`sql
//数据删除的范围由WHERE查询子句决定
ALTER TABLE partition_v2 DELETE WHERE ID = ‘A003’



