The Google File System (一): Master的三个身份
GFS的设计决策
第一个以工程上”简单“作为设计原则
GFS 直接使用了 Linux 服务上的普通文件作为基础存储层,并且选择了最简单的单 Master 设计。单 Master 让 GFS 的架构变得非常简单,避免了需要管理复杂的一致性问题。不过它也带来了很多限制,比如一旦 Master 出现故障,整个集群就无法写入数据,而恢复 Master 则需要运维人员手动操作,所以 GFS 其实算不上一个高可用的系统。
第二个是根据硬件特性来进行设计取舍
第三个是根据实际应用特性,放宽了数据一致性(Consistency)的选择
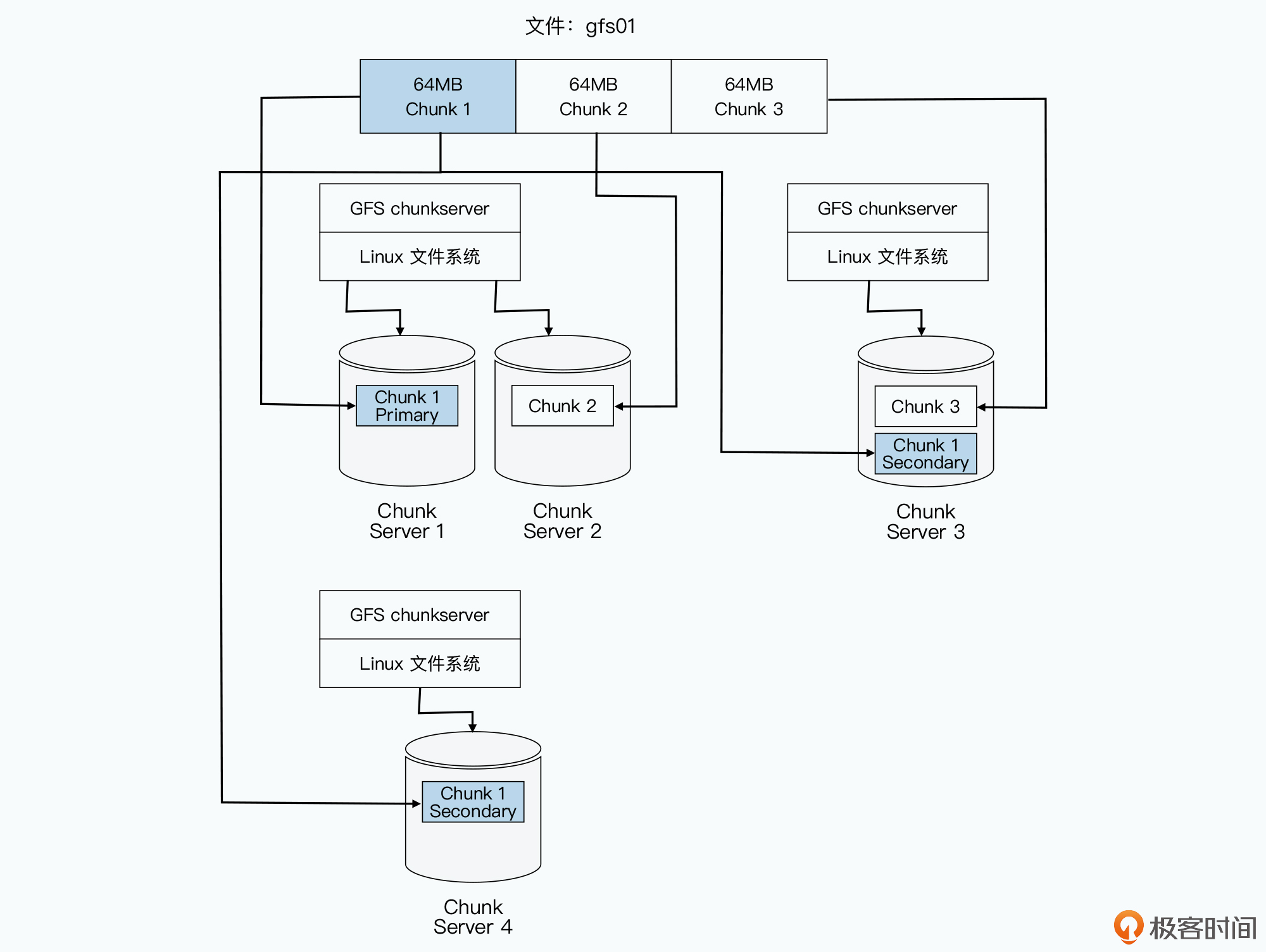
1、相对于存储数据的 Chunkserver,Master 是一个目录服务
在 GFS 里面,会把每一个文件按照 64MB 一块的大小,切分成一个个 chunk。每个 chunk 都会有一个在 GFS 上的唯一的 handle,这个 handle 其实就是一个编号,能够唯一标识出具体的 chunk。然后每一个 chunk,都会以一个文件的形式,放在 chunkserver 上。
而 chunkserver,会负责和 master 以及 GFS 的客户端进行 RPC 通信,完成实际的数据读写操作。当然,为了确保数据不会因为某一个 chunkserver 坏了就丢失了,每个 chunk 都会存上整整三份副本(replica)。其中一份是主数据(primary),两份是副数据(secondary),当三份数据出现不一致的时候,就以主数据为准。有了三个副本,不仅可以防止因为各种原因丢数据,还可以在有很多并发读取的时候,分摊系统读取的压力。
2、相对于为了灾难恢复的 Backup Master,它是一个同步复制的主从架构下的主节点;
主从服务器进行数据的同步复制,确保Master节点故障了,有backup节点可用,保障可用性,只有所有的backup Master写入成功,才算成功
为了缓解Master节点压力,Master的所有数据都是保存在内存里,Master会通过记录操作日志和定期生成对应的CheckPoints进行持久化,也就是写到硬盘上,Master节点重启时,会读取最新的CheckPoints,然后重放之后的操作日志进行恢复。
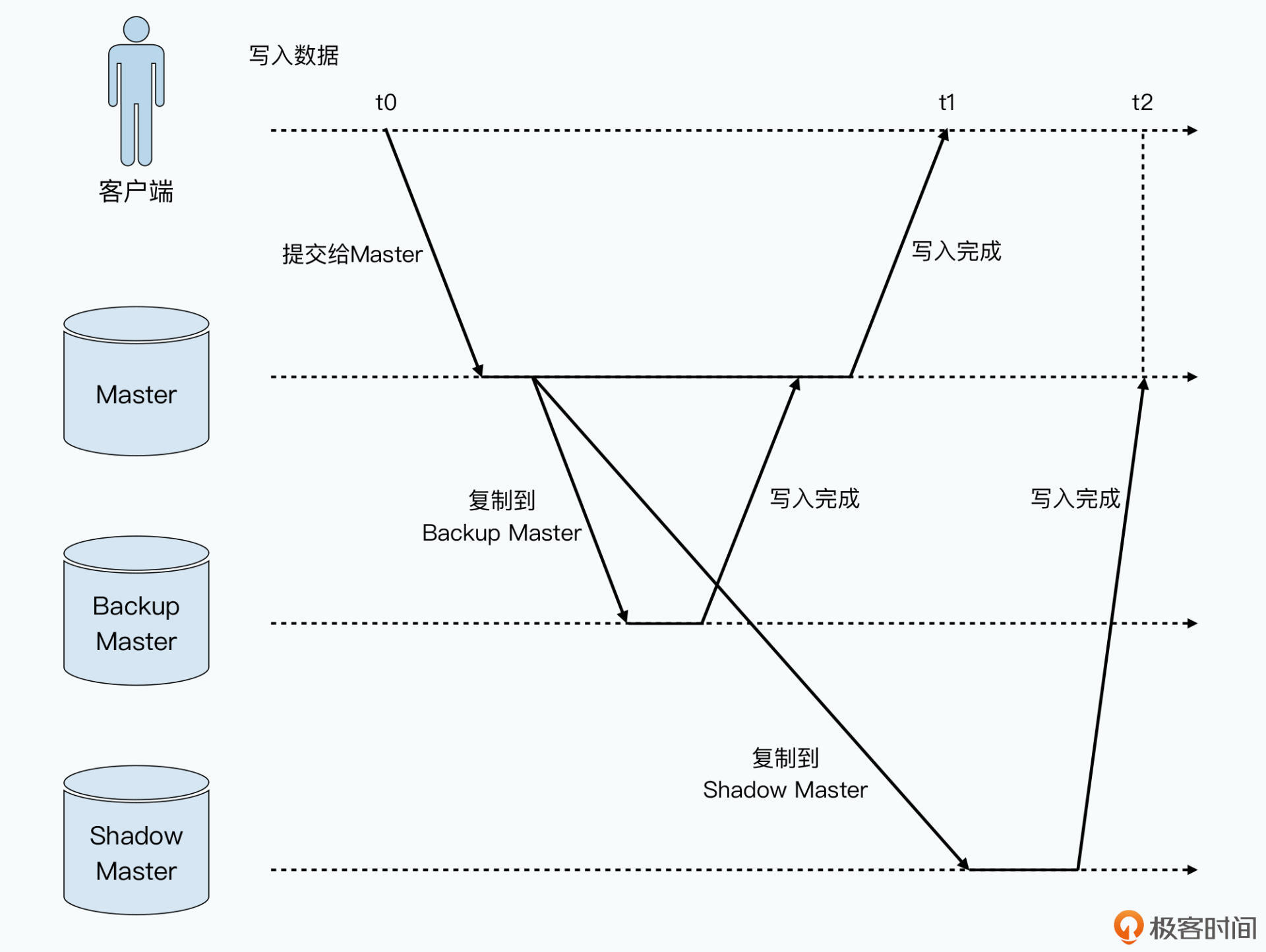
3、相对于为了保障读数据的可用性而设立的 Shadow Master,它是一个异步复制的主从架构下的主节点。
为了保障节点挂了,进行新节点切换,快速恢复期间,数据仍然可读,加入了一系列的影子Master, 走数据的异步复制。
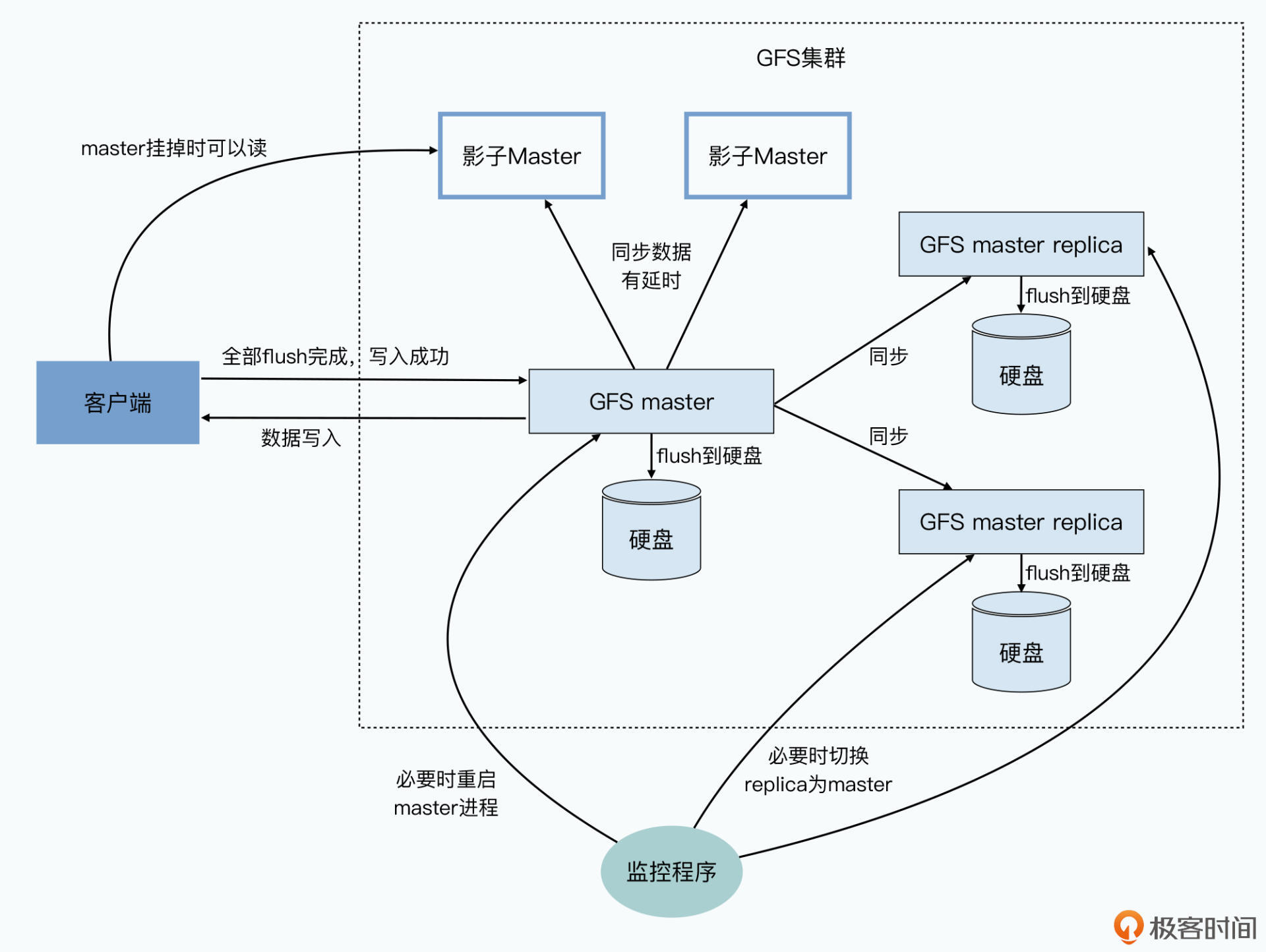
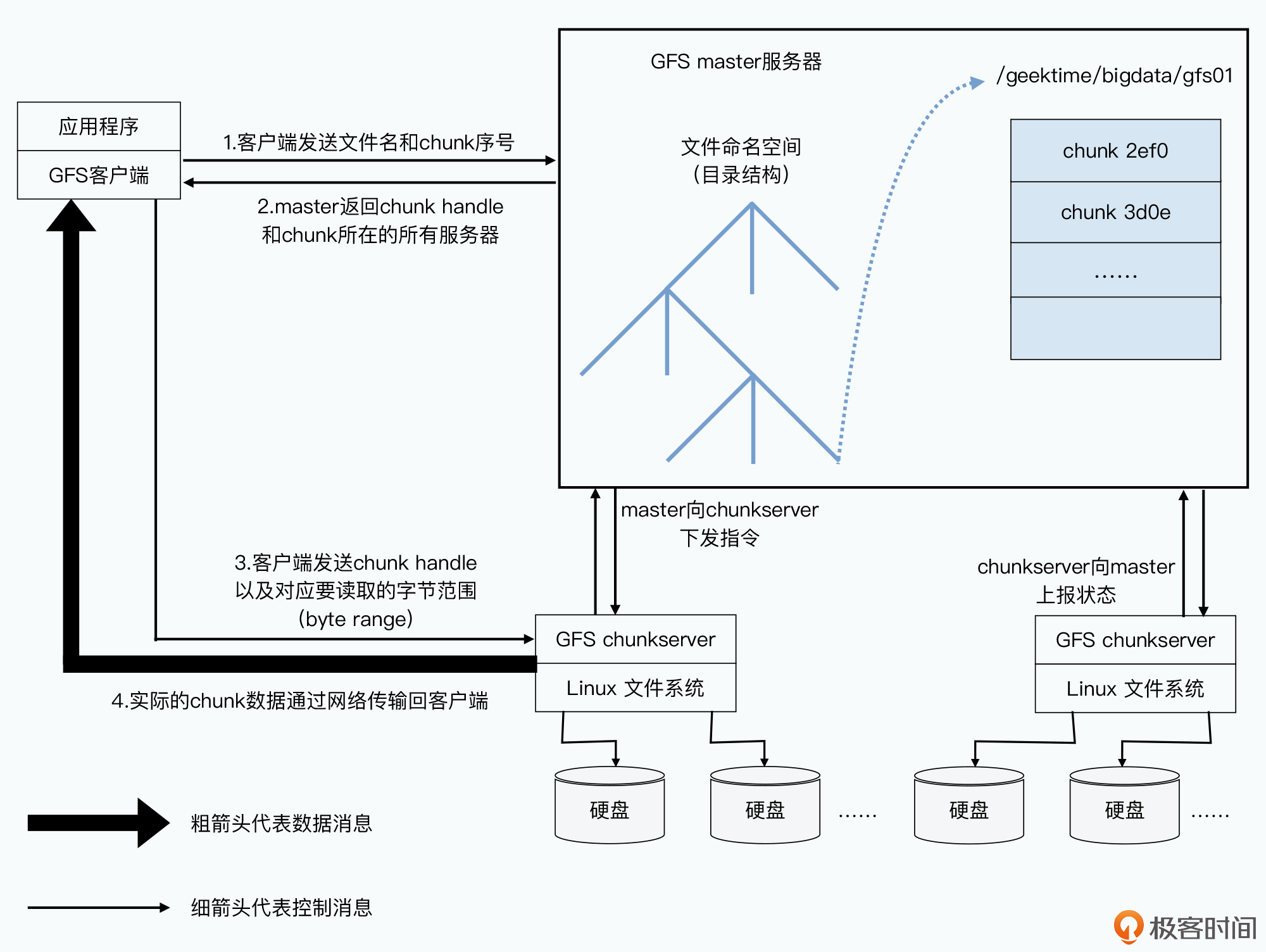
客户端读取数据的整个过程指令流向
The Google File System (二): 如何应对网络瓶颈?
GFS的数据写入
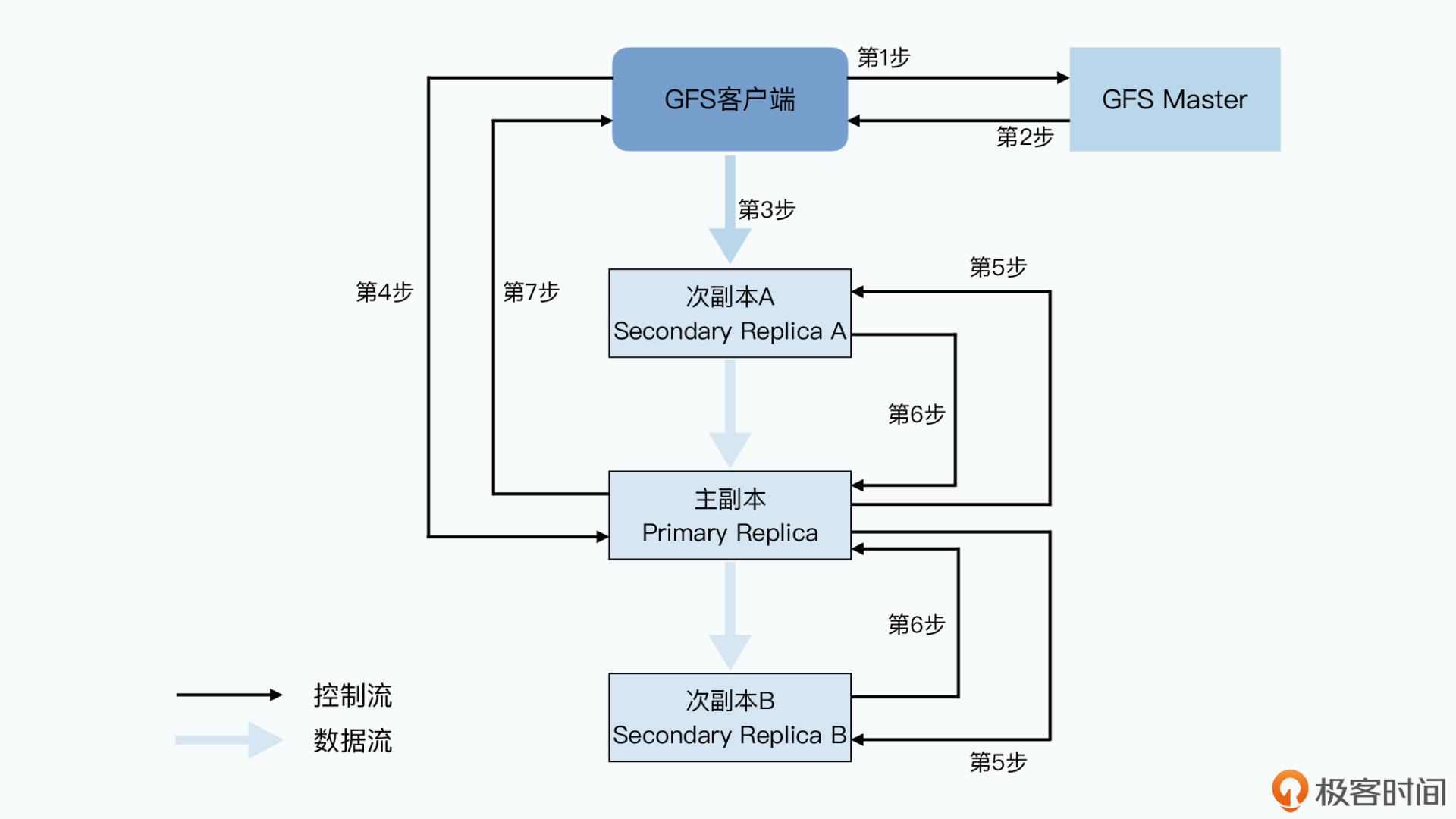
- 第一步,客户端会去问 master 要写入的数据,应该在哪些 chunkserver 上。
- 第二步,和读数据一样,master 会告诉客户端所有的次副本(secondary replica)所在的 chunkserver。这还不够,master 还会告诉客户端哪个 replica 是“老大”,也就是主副本(primary replica),数据此时以它为准。
- 第三步,拿到数据应该写到哪些 chunkserver 里之后,客户端会把要写的数据发给所有的 replica。不过此时,chunkserver 拿到发过来的数据后还不会真的写下来,只会把数据放到LRU缓冲区里
- 第四步,等到所有次副本都接收完数据后,客户端就会发送一个写请求给到主副本。
- 第五步,主副本会把对应的写请求转发给所有的次副本,所有次副本会和主副本以同样的数据写入顺序,把数据写入到硬盘上。
- 第六步,次副本的数据写入完成之后,会回复主副本,我也把数据和你一样写完了。
- 第七步,主副本再去告诉客户端,这个数据写入成功了。而如果在任何一个副本写入数据的过程中出错了,这个出错都会告诉客户端,也就意味着这次写入其实失败了。
GFS解决网络带宽瓶颈的方法
- 分离控制流和数据流:Master只做元数据管理,数据写入不通过Master,从而避免了Master成为瓶颈 ,实际的数据传输过程和提供写入指令的动作是完全分离的。
- 流水式的网络数据传输,客户端传输数据,传输给到网络里离自己最近的次副本A,然后副本A一边接收数据,一边把数据传输给距离自己最近的另外一个副本。
- 独特的Snapshot操作:文件复制指令,客户端下发复制指令,指令通过控制流,下发到主副本服务器,次副本服务器,会在chunkserver本地执行数据复制,不再需要通过网络传输进行复制。
MapReduce(一):源起Unix的设计思想
MapReduce 编程模型
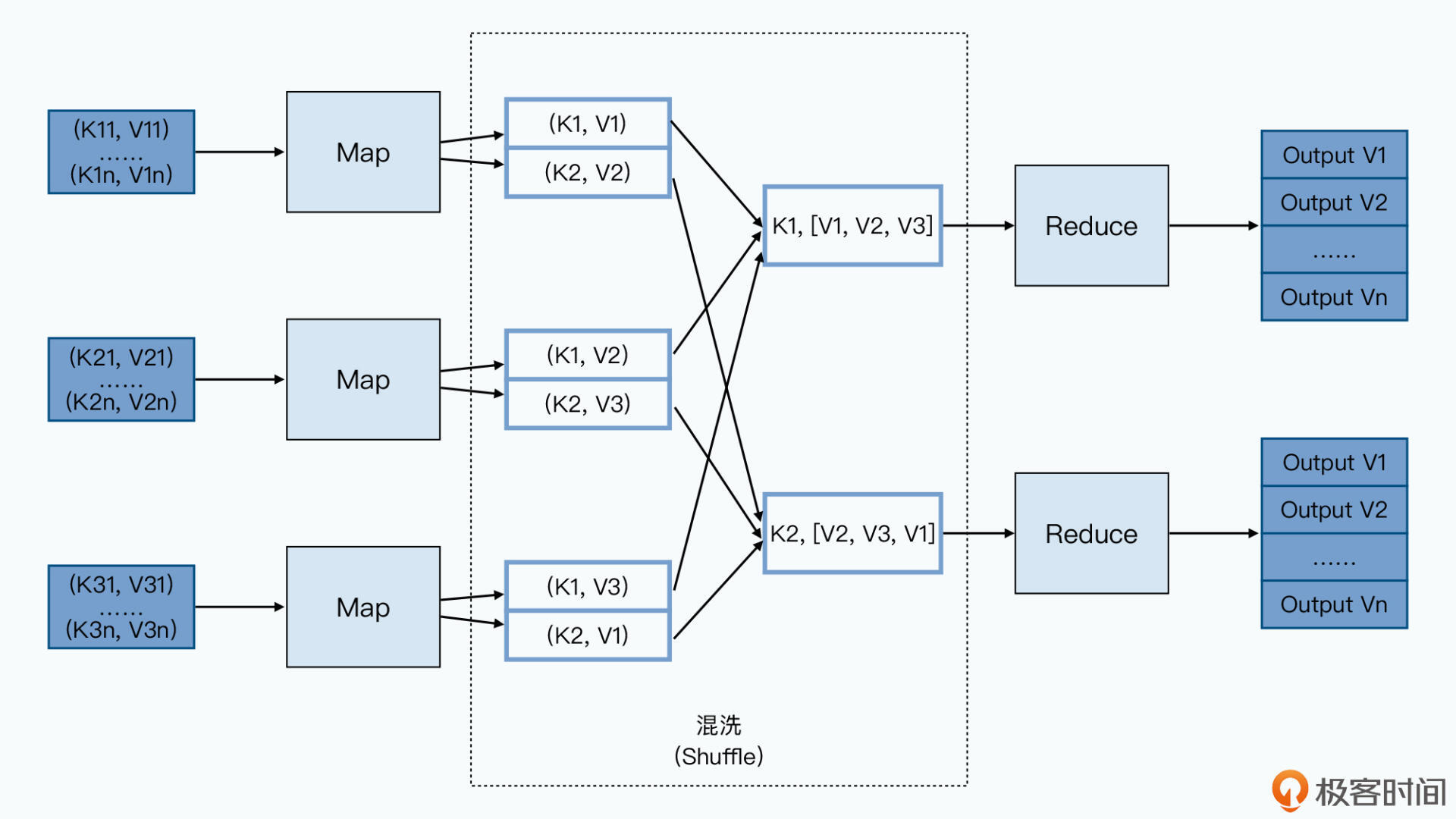
Map 函数,顾名思义就是一个映射函数,它会接受一个 key-value 对,然后把这个 key-value 对转换成 0 到多个新的 key-value 对并输出出去。
map(k1,v1) -> list(k2,v2)
Reduce 函数,则是一个函数,它接受一个 Key,以及这个 Key 下的一组 Value,然后化简成一组新的值 Value 输出出去。
reduce(k2,list(v2)) -> list(v3)
MapReduce应用场景
分布式grep


