1. 面经总结
1.1. hashmap的底层数据结构,put的过程。
JDK1.7 ,HashMap底层是数据和链表结合在一起使用,也就是链表散列
JDK1.8 ,HashMap底层是数据和链表和红黑树结合一起使用
jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
put过程
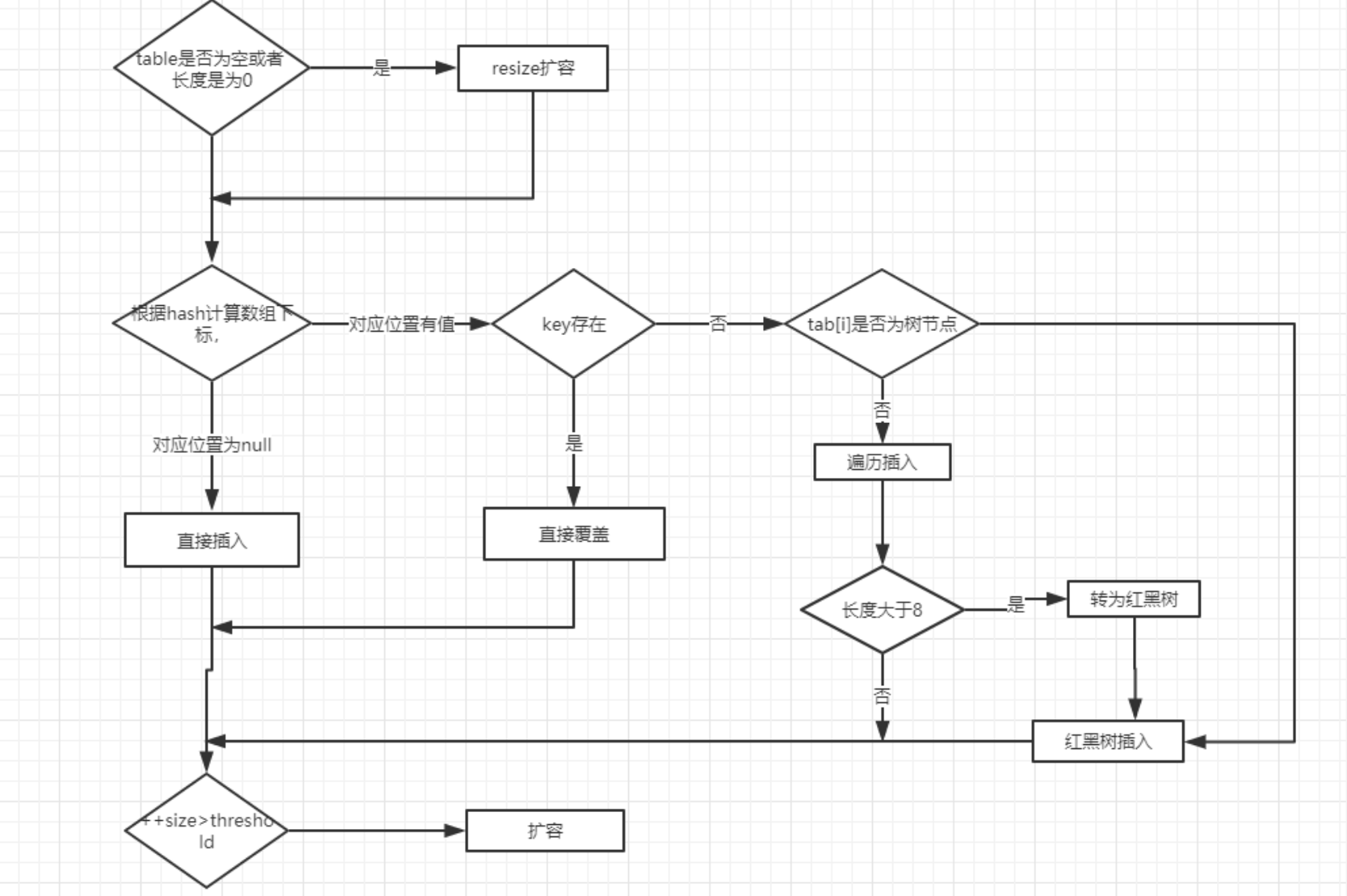
1.2. Hashmap是否是线程安全的,多线程下会有什么问题?concurrentHashMap底层是如何实现线程安全的。
HashMap不是线程安全的,HashTable 和concurrentHashMap是线程安全的,HashTable 是全局锁,HashTable容器使用synchronized来保证线程安全,concurrentHashMap分段锁,性能更高。
HashMap在多线程下会出现死循环问题
原因:HashMap出现死循环的条件是,当两个线程同时对原有的旧的Hash表扩容时,当其中一个线程正在扩容时(遍历单向链表)切换到另外一个线程进行扩容操作,并且在线程二中完成了所有的扩容操作,此时再切换到线程1中就可能造成单向链表形成一个环,从而在下一次查询操作时就可能发生死循环。
concurrentHashMap底层是如何实现线程安全的?
ConcurrentHashMap采用的是分段式锁,可以理解为把一个大的Map拆封成N个小的Segment,在put数据时会根据hash来确定具体存放在哪个Segment中,Segment内部的同步机制是基于ReentryLock操作的,每一个Segment都会分配一把锁,当线程占用锁访问其中一段数据时,其他段的数据也能被其他线程访问,也就是实现并发访问。
能说一下ConcurrentHashMap在JDK1.7和JDK1.8中的区别吗?
- JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点)
- JDK1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了
- JDK1.8使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表,这样形成一个最佳拍档
1.3. synchronized实现原理与锁的升级过程。
锁的升级过程
升级过程简单理解为: 偏向锁 -> 轻量级锁 -> 重量级锁
synchronized实现原理
synchronized 同步语句块的实现使用的是 monitorenter 和 monitorexit 指令,其中 monitorenter 指令指向同步代码块的开始位置,monitorexit 指令则指明同步代码块的结束位置。
synchronized 修饰的方法并没有 monitorenter 指令和 monitorexit 指令,取得代之的确实是 ACC_SYNCHRONIZED 标识,该标识指明了该方法是一个同步方法。 不过两者的本质都是对对象监视器 monitor 的获取。
在执行monitorenter时,会尝试获取对象的锁,如果锁的计数器为 0 则表示锁可以被获取,获取后将锁计数器设为 1 也就是加 1。
在执行 monitorexit 指令后,将锁计数器设为 0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
1.4. 数据库是否用了索引?用explain无法看出索引用了哪一部分?
遇到非等值判断时匹配停止
a = ? and b = ? and c= ?
a = ? and b = ? and c > ?
a = ? and b > ? and c > ?, 只用到索引的一部分(a,b),因为b把数据阻断了,b不是定植时,c时无序的,无法使用(a,b,c)索引
1.5. spring循环引用的问题,A->B->A问题,怎么解决
Spring 为了解决单例的循环依赖问题,使用了三级缓存。其中一级缓存为单例池(singletonObjects),二级缓存为提前曝光对象(earlySingletonObjects),三级缓存为提前曝光对象工厂(singletonFactories)。
假设A、B循环引用,实例化 A 的时候就将其放入三级缓存中,接着填充属性的时候,发现依赖了 B,同样的流程也是实例化后放入三级缓存,接着去填充属性时又发现自己依赖 A,这时候从缓存中查找到早期暴露的 A,没有 AOP 代理的话,直接将 A 的原始对象注入 B,完成 B 的初始化后,进行属性填充和初始化,这时候 B 完成后,就去完成剩下的 A 的步骤,如果有 AOP 代理,就进行 AOP 处理获取代理后的对象 A,注入 B,走剩下的流程。
1.6. 举个不用回表的例子
回表:数据库根据索引找到了指定的记录所在行后,还需要根据rowid再次到数据块里取数据的操作。 比如:select code from order where mcode = ‘M001’;因为mcode索引,所以查询mcode的索引,查到符合要求的数据的rowid(索引内是不会保存具体数据的),再根据rowid,查询到具体的数据,拿到code。
如何避免回表
使用覆盖索引。
使用mcode的索引,使用(mcode,code)的联合索引。 在查找到mcode的索引后,可以直接拿到code了,不需要再回表。
1.7. Mysql主键用uuid会有什么问题?
主键一般使用 mysql的自增主键、uuid、雪花算法。
自增主键:减少了页分裂和碎片的产生 效率最高
uuid: uuid毫无规律、新增的值不一定比之前的主键值大,所以innodb无法总数将新行插入到索引的最后
- ① 写入的目标页很可能已经刷新到磁盘上并且从缓存上移除,或者还没有被加载到缓存中,innodb在插入之前不得不先找到并从磁盘读取目标页到内存中,这将导致大量的随机IO
- ②因为写入是乱序的,innodb不得不频繁的做页分裂操作,以便为新的行分配空间,页分裂导致移动大量的数据,一次插入最少需要修改三个页以上
- ③由于频繁的页分裂,页会变得稀疏并被不规则的填充,最终会导致数据会有碎片
1.8. 聚蔟索引和非聚蔟索引的区别,是否分别对应主键索引、辅助索引? 是的
聚簇索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据.
非聚簇索引:将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置.
1.9. jvm垃圾回收是如何做的?
- 标记清除算法 ,产生内存碎片
- 标记整理算法 ,GC暂停时间会加长
- 复制算法, 内存空间使用率只有50%,可分配内存减少了一半
- 分代收集算法,分为eden和survivor区, Survivor 由 FromSpace与ToSpace组成,新生代复制算法来完成收集,老年代使用用“标记-清除”算法或“标记-整理”算法来进行回收。
特别地,在分代收集算法中,对象的存储具有以下特点: 对象优先在 Eden 区分配。 大对象直接进入老年代。 长期存活的对象将进入老年代,默认为 15 岁。
1.10. jvm运行时有哪些数据区
- 程序计数器:记录程序执行的位置,有了程序计数器,就可以保证在涉及线程上下文切换的情景下,程序依然能够正确无误地运行下去。
- Java虚拟机栈:存着程序运行时的局部变量,主要包含局部变量表、操作数栈。
- 本地方法栈:为native方法服务
- 方法区:线程共享,用于存储类的元信息、静态变量、常量、全局变量、普通方法的字节码等内容。
- 堆:线程共享、存储实例对象和数组
1.11. java垃圾回收器有哪些
- Serial(串行GC)收集器 ...
- ParNew(并行GC)收集器 ...
- Parallel Scavenge(并行回收GC)收集器 ...
- Serial Old(串行GC)收集器 ...
- Parallel Old(并行GC)收集器 ...
- CMS(并发GC)收集器 ...
- G1收集器
1.12. 哈希冲突如何解决
- 开放寻址法,冲突则根据指定步长向后寻找直到找到空位或没有位置。
- 再哈希发,有多个不同的Hash函数,当发生冲突时,使用第二个,第三个,等哈希函数 直到不再冲突。
- 建立公共溢出区, 将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表 ,缺点: 如未能命中哈希表 需要遍历查找溢出表 查询效率低。
- 拉链法 ,如出现冲突,将其作为链表一个节点加入头或者尾巴处。